cowsay "Bienvenido"
Pipeline de Analytics en AWS para Historial de Spotify
Este proyecto presenta un pipeline de análisis de datos que extrae el historial de reproducción de música de Spotify utilizando su API. Los datos obtenidos se almacenan en un bucket de Amazon S3 y se procesan utilizando AWS Glue. Finalmente, los resultados se visualizan mediante Amazon QuickSight, permitiendo obtener insights sobre los hábitos de escucha y preferencias musicales.
Arquitectura del pipeline de Analytics
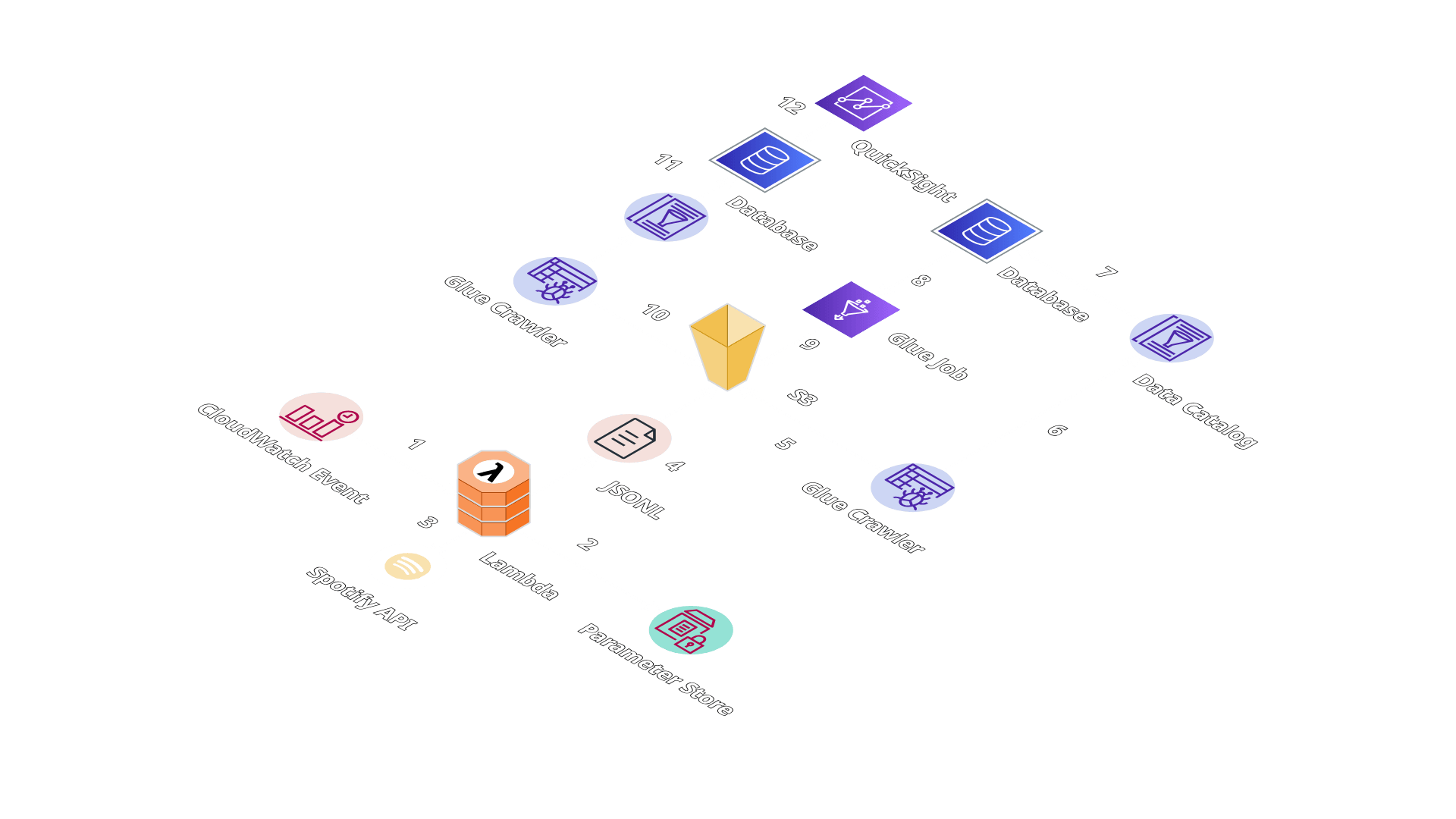
La arquitectura del pipeline de Analytics sigue el siguiente flujo:
Extracción y almacenamiento del historial de Spotify (1, 2, 3, 4): La extracción del historial de reproducción se ejecuta automáticamente a través de una función Lambda que se activa diariamente mediante EventBridge. Esta función se conecta a la API de Spotify utilizando credenciales seguras almacenadas en AWS Parameter Store, extrae los datos de reproducción y los guarda en un bucket de Amazon S3 en formato JSONL.
Limpieza y transformación de datos (5, 6, 7, 8, 9): Dado que el historial de canciones reproducidas extraído puede contener registros duplicados, es necesario realizar un proceso de limpieza y transformación para obtener un formato que facilite el análisis posterior. Este proceso se ejecuta en dos etapas: Primero, Glue Crawler extrae los registros en bruto desde S3 y crea automáticamente un esquema en AWS Glue Data Catalog, estructurando los datos en una base de datos catalogada. Posteriormente, un Glue Job toma estos datos catalogados como origen, ejecuta las tareas de limpieza y deduplicación, transforma los registros al formato Parquet optimizado, y almacena el resultado final en S3.
Visualización de datos (10, 11, 12): Para garantizar que el esquema de datos permanezca actualizado después del proceso de limpieza y transformación, se ejecuta un segundo Glue Crawler que analiza los datos procesados en S3 y define un nuevo esquema optimizado en AWS Glue Data Catalog. Finalmente, AWS QuickSight se conecta a estos datos catalogados para crear dashboards y visualizaciones interactivas que permiten obtener insights detallados sobre los hábitos de escucha musical en Spotify.
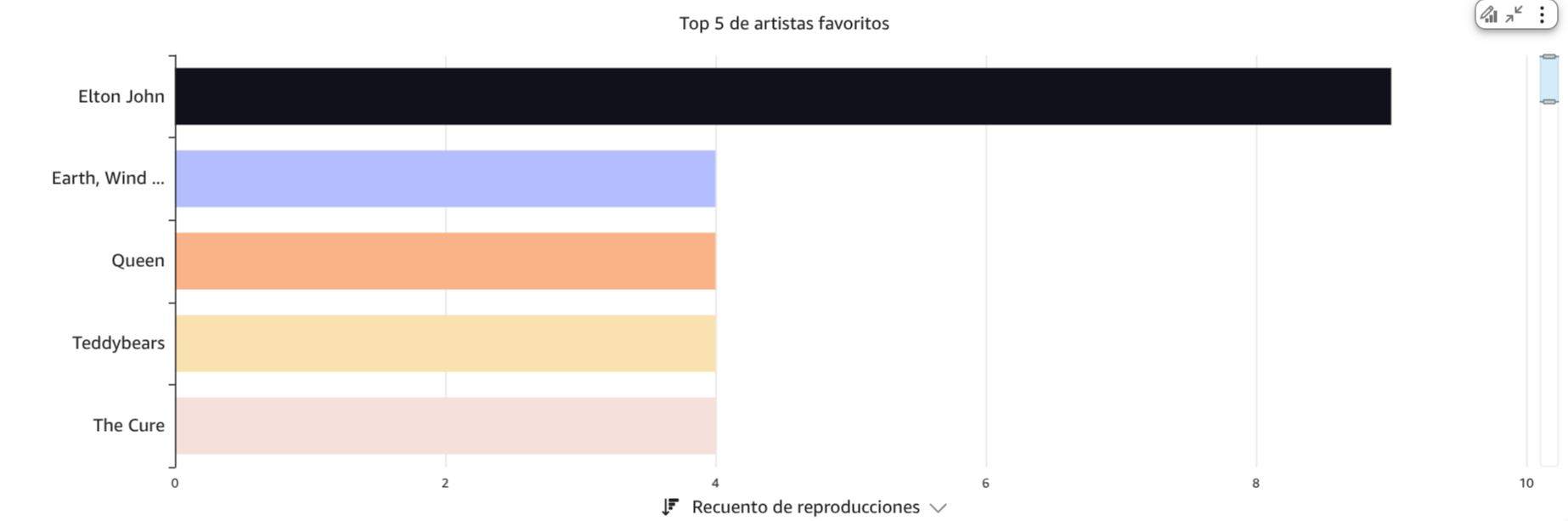
Mis 5 artistas más escuchados en Spotify
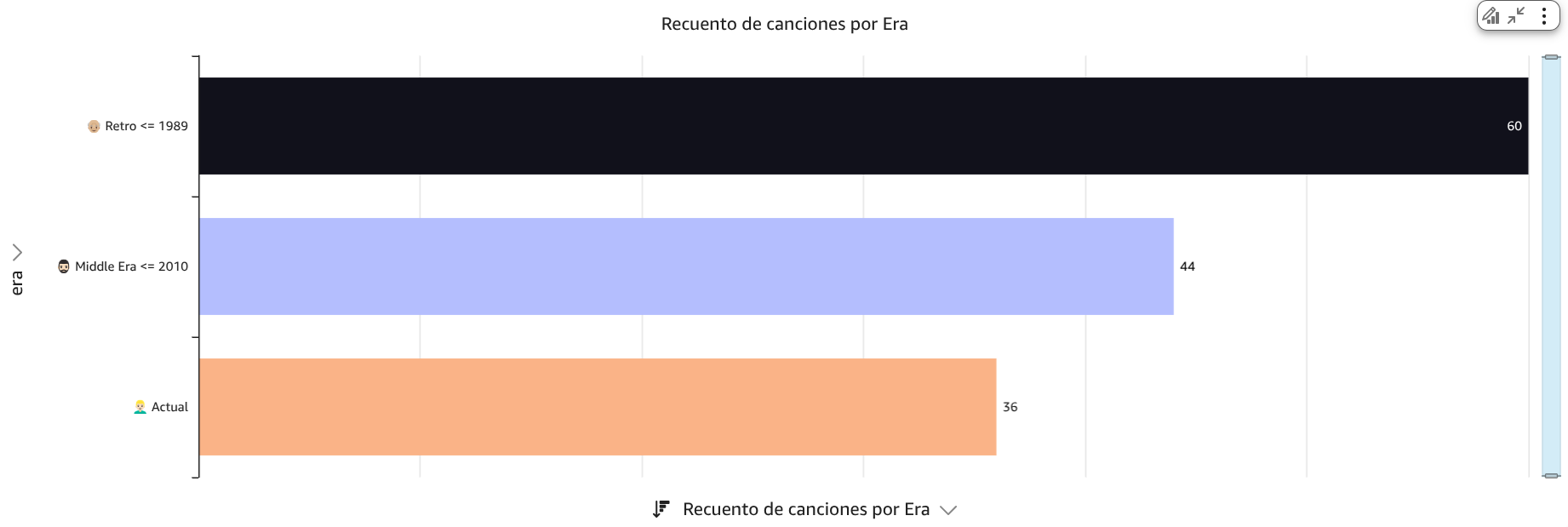
Mis preferencias de acuerdo a cada era
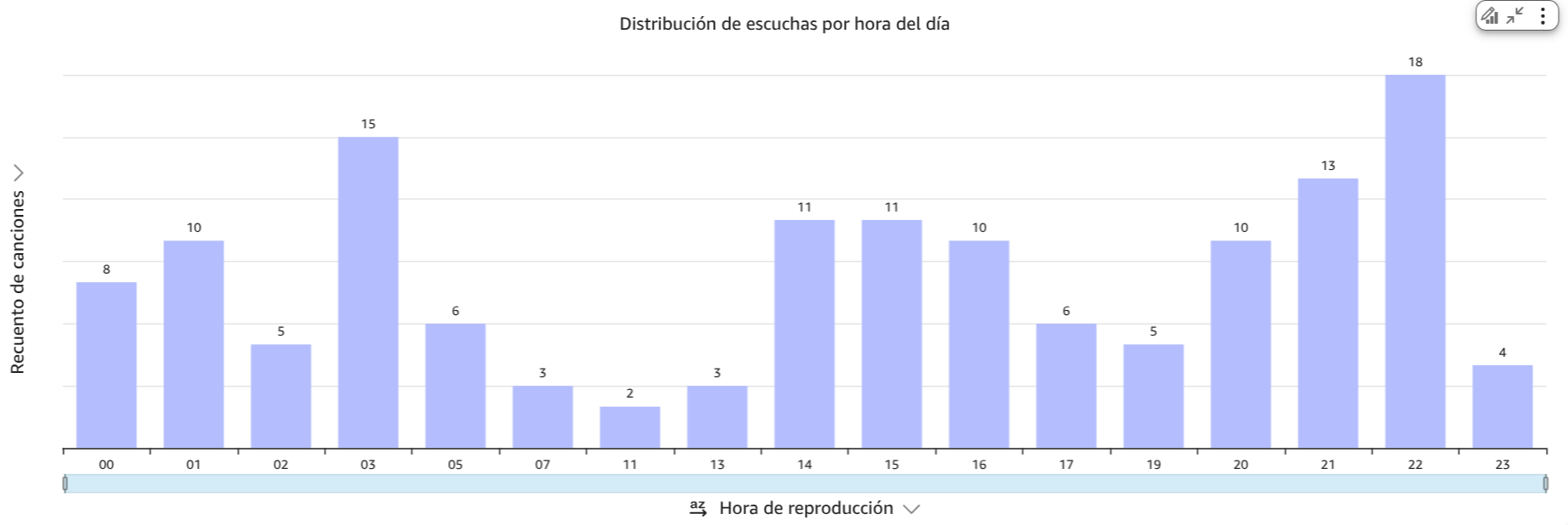
Mis hábitos de escucha de acuerdo a la hora del día
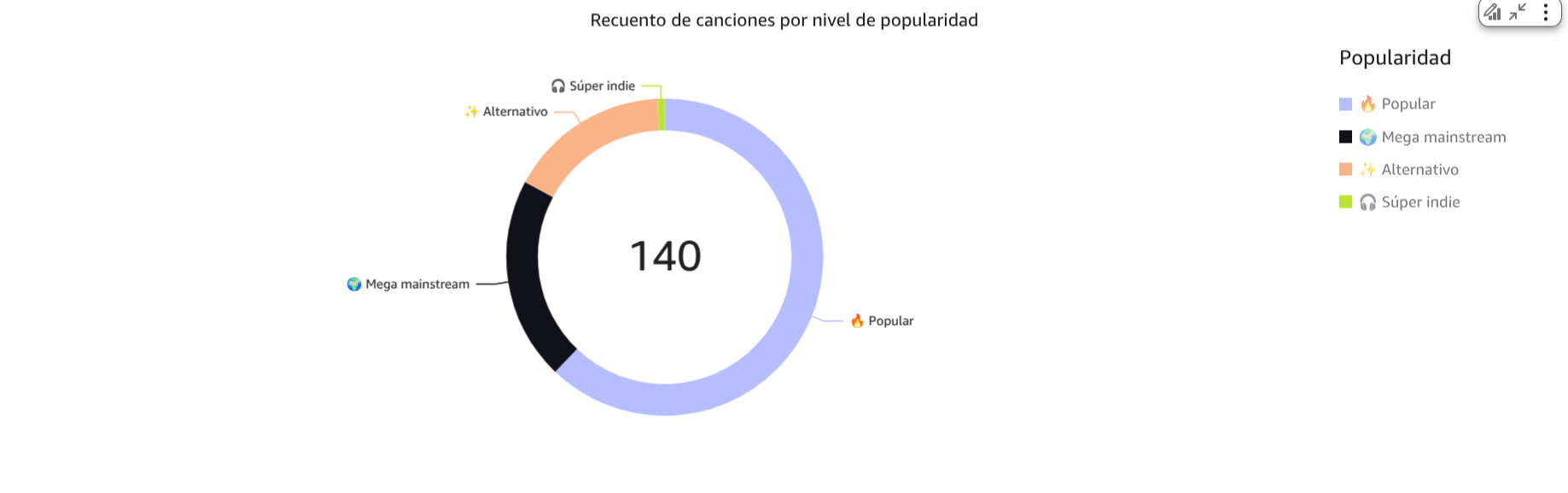
Mis preferencias de acuerdo a la popularidad de las canciones
Conclusiones y Repositorio en GitHub del Proyecto
AWS proporciona un ecosistema completo de servicios que facilita la construcción de pipelines de datos automatizados y escalables, adaptables a diferentes necesidades de análisis. En este proyecto se implementó una arquitectura integral donde AWS Lambda, en combinación con EventBridge y Parameter Store, extrae automáticamente el historial de reproducción de Spotify de forma diaria y lo almacena en S3. Posteriormente, AWS Glue ejecuta los procesos de limpieza y transformación de datos al formato Parquet optimizado, proporcionando una base sólida para que QuickSight genere visualizaciones interactivas y análisis detallados de los hábitos musicales. El código de la función Lambda y el script del Glue Job están disponibles en el siguiente enlace para consulta y referencia. spotify-history-analytics
Sitio alojado en AWS Amplify
Built with Reflex